Stephen Wolfram explores minimal models and their visualizations, aiming to explain the underneath functionality of neural nets and ultimately machine learning.
I’ve only made it about half way through as of right now. Like I stated previously, I’m not an expert. But I still believe in my statement above. From what I can gather it takes extreme amounts of effort to even figure out how a neural network arrived at the conclusion it came up with. And that still seems like a backwards way of approaching it. You’re starting at the end and working your way backwards. It’s not a bad method. Just in my opinion I believe it’s the wrong method.
If you compare this to something like a scientific theory it doesn’t quite match up to the procedure. Things like gravity exist regardless of the formulas used to determine it. Because of this we were able to figure out the formulas required to calculate it. With neural network’s we already know how they do what they do because we are the ones that programmed them, at least initially. I find it more analogous to solving for the velocity of an object falling over and over again. You already know the formula, so it’s relatively easy. You just work your way backwards from the result. Sure we can add things like drag, friction, and terminal velocity to add more parameterization and make it more accurate. But even with something like this, the increase in accuracy slowly decreases while the processing power increases.
Basically what I’m trying to say is that I believe the “formula” is not quite correct. It’s adjacent to what we are looking for. You can keep making the initial conditions as complicated as you want but eventually you will reach the realistic computational limitations of said conditions. If the initial conditions are not quite correct, you can only get it within a certain degree of accuracy before it starts to either diverge or plateau.
I’m not saying neural network’s are wrong. I’m saying that we are making the wrong kinds of neural network’s. Instead of forcing massive amounts of data into these things until we get the result we want, we should try and find more ideal initial conditions that are more equipped to solve the problems we are trying to solve. As I mentioned above the result doesn’t matter when the method of solving has unnecessary, or even incorrect, steps involved in the processes.
I am a layman when it comes to neural networks and machine learning, as I stated above. But this is what I see whenever I hear about this kinda stuff. It just all seems so wasteful because we are so focused on the results. It feels like a confirmation bias when we see the results we were expecting so we ignore the underlying issues. If the “black box” is causing issues it seems entirely more likely that it was set up for failure. If you were calculating a theoretical pendulum and it starts doing 360 no scopes instead of going back and forth then the laws and conditions assigned to it were incorrect.
Edit: Added some stuff in case I explained my train if thought poorly.
I don’t think that this critique is focused enough to be actionable. It doesn’t take much effort to explain why a neural network made a decision, but the effort scales with the size of the network, and LLMs are quite large, so the amount of effort is high. See recent posts by (in increasing disreputability of sponsoring institution) folks at MIT and University of Cambridge, Cynch.ai, Apart Research, and University of Cambridge, and LessWrong. (Yep, even the LW cultists have figured out neural-net haruspicy!)
I was hoping that your complaint would be more like Evan Miller’s Transformers note, which lays out a clear issue in the Transformers arithmetic and gives a possible solution. If this seems like it’s over your head right now, then I’d encourage you to take it slowly and carefully study the maths.
Fair enough. I’m still at work so I’ve only skimmed these so far. I appreciate the feedback and links and I’ll definitely look into it more.
I completely agree that my critique isn’t focused enough. I slapped that comment together entirely too fast without much deeper thought involved. I have a very surface level understanding of this kinda stuff. Regardless, I do like sharing my opinion from an outsiders perspective. Mostly because I enjoy the discussion. It’s always an opportunity to learn something new, even if it ruffles a few feathers along the way. I know that whenever I’m super invested in a topic, no matter what it is, I sometimes get so soaked up in it all that I tend to ignore outside influences.


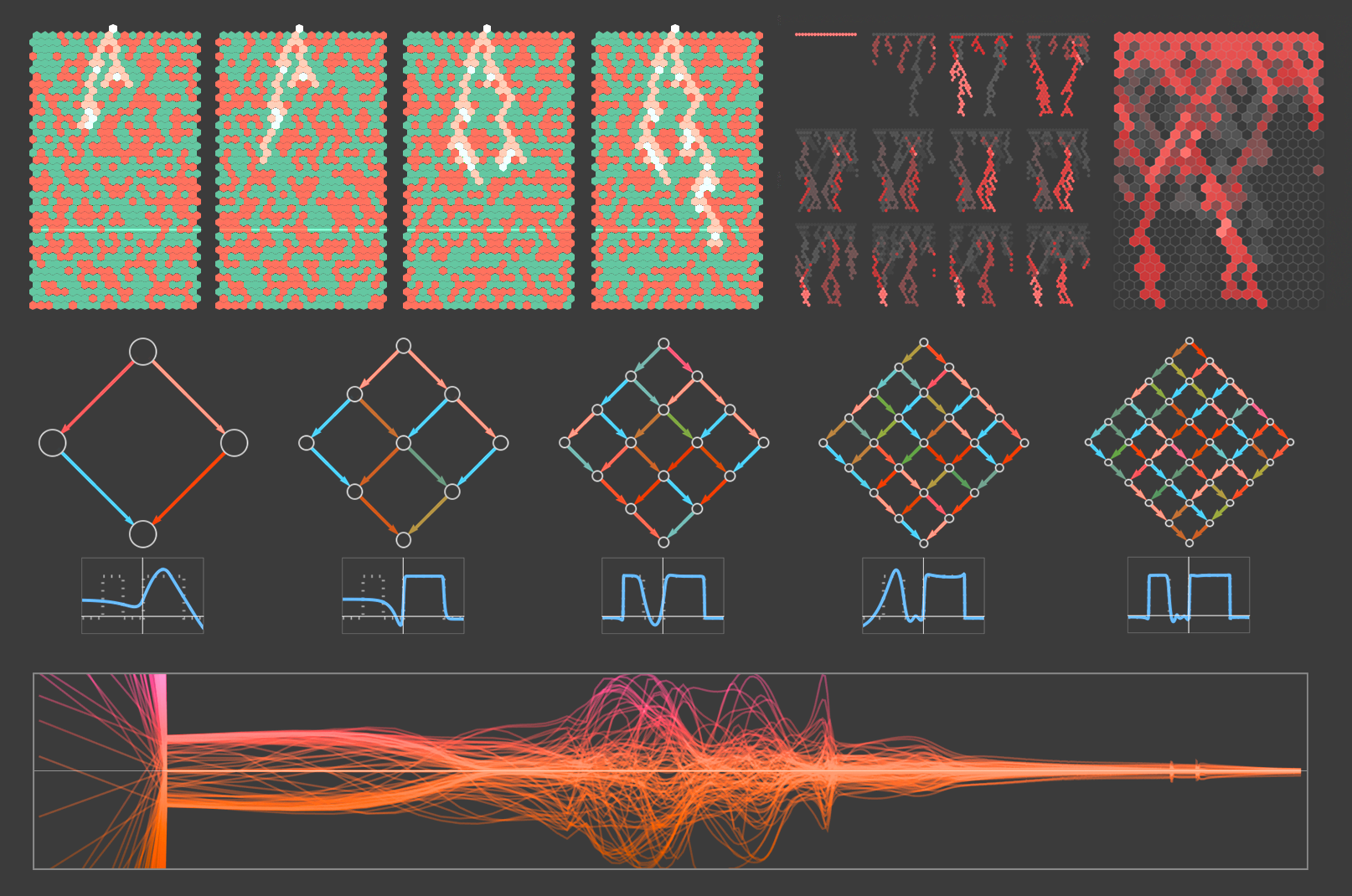
What do you think about what Steven Wolfram wrote here?
I’ve only made it about half way through as of right now. Like I stated previously, I’m not an expert. But I still believe in my statement above. From what I can gather it takes extreme amounts of effort to even figure out how a neural network arrived at the conclusion it came up with. And that still seems like a backwards way of approaching it. You’re starting at the end and working your way backwards. It’s not a bad method. Just in my opinion I believe it’s the wrong method.
If you compare this to something like a scientific theory it doesn’t quite match up to the procedure. Things like gravity exist regardless of the formulas used to determine it. Because of this we were able to figure out the formulas required to calculate it. With neural network’s we already know how they do what they do because we are the ones that programmed them, at least initially. I find it more analogous to solving for the velocity of an object falling over and over again. You already know the formula, so it’s relatively easy. You just work your way backwards from the result. Sure we can add things like drag, friction, and terminal velocity to add more parameterization and make it more accurate. But even with something like this, the increase in accuracy slowly decreases while the processing power increases.
Basically what I’m trying to say is that I believe the “formula” is not quite correct. It’s adjacent to what we are looking for. You can keep making the initial conditions as complicated as you want but eventually you will reach the realistic computational limitations of said conditions. If the initial conditions are not quite correct, you can only get it within a certain degree of accuracy before it starts to either diverge or plateau.
I’m not saying neural network’s are wrong. I’m saying that we are making the wrong kinds of neural network’s. Instead of forcing massive amounts of data into these things until we get the result we want, we should try and find more ideal initial conditions that are more equipped to solve the problems we are trying to solve. As I mentioned above the result doesn’t matter when the method of solving has unnecessary, or even incorrect, steps involved in the processes.
I am a layman when it comes to neural networks and machine learning, as I stated above. But this is what I see whenever I hear about this kinda stuff. It just all seems so wasteful because we are so focused on the results. It feels like a confirmation bias when we see the results we were expecting so we ignore the underlying issues. If the “black box” is causing issues it seems entirely more likely that it was set up for failure. If you were calculating a theoretical pendulum and it starts doing 360 no scopes instead of going back and forth then the laws and conditions assigned to it were incorrect.
Edit: Added some stuff in case I explained my train if thought poorly.
Interesting, it reminds me of Ptolemy adding more and more epicycles to explain observations, instead of considering that his model was wrong.
https://en.m.wikipedia.org/wiki/Deferent_and_epicycle#The_number_of_epicycles
I don’t think that this critique is focused enough to be actionable. It doesn’t take much effort to explain why a neural network made a decision, but the effort scales with the size of the network, and LLMs are quite large, so the amount of effort is high. See recent posts by (in increasing disreputability of sponsoring institution) folks at MIT and University of Cambridge, Cynch.ai, Apart Research, and University of Cambridge, and LessWrong. (Yep, even the LW cultists have figured out neural-net haruspicy!)
I was hoping that your complaint would be more like Evan Miller’s Transformers note, which lays out a clear issue in the Transformers arithmetic and gives a possible solution. If this seems like it’s over your head right now, then I’d encourage you to take it slowly and carefully study the maths.
Fair enough. I’m still at work so I’ve only skimmed these so far. I appreciate the feedback and links and I’ll definitely look into it more.
I completely agree that my critique isn’t focused enough. I slapped that comment together entirely too fast without much deeper thought involved. I have a very surface level understanding of this kinda stuff. Regardless, I do like sharing my opinion from an outsiders perspective. Mostly because I enjoy the discussion. It’s always an opportunity to learn something new, even if it ruffles a few feathers along the way. I know that whenever I’m super invested in a topic, no matter what it is, I sometimes get so soaked up in it all that I tend to ignore outside influences.