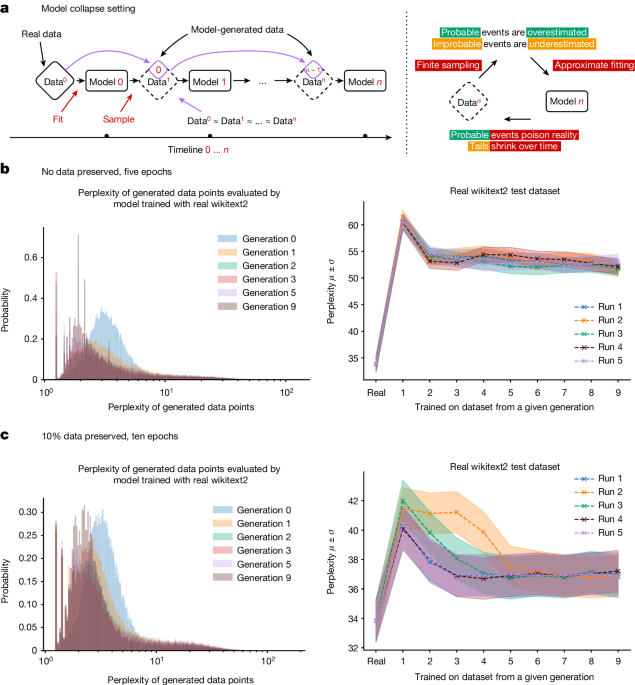
Analysis shows that indiscriminately training generative artificial intelligence on real and generated content, usually done by scraping data from the Internet, can lead to a collapse in the ability of the models to generate diverse high-quality output.
We find that preservation of the original data allows for better model fine-tuning and leads to only minor degradation of performance
That means, as long as generated content isn’t like 90% of the Internet, they’ll be fine. Even then, you can find relatively easy ways to sift data for generated content. Doesn’t even have to be perfect.
What really bothers me here is that we might create a world, where the typical AI style of writing takes over the world, because the AI learns on itself, and the companies simply don’t care about it. That’s not really a collapse as such, but a narrowing.
That means, as long as generated content isn’t like 90% of the Internet, they’ll be fine. Even then, you can find relatively easy ways to sift data for generated content. Doesn’t even have to be perfect.
What really bothers me here is that we might create a world, where the typical AI style of writing takes over the world, because the AI learns on itself, and the companies simply don’t care about it. That’s not really a collapse as such, but a narrowing.
this sounds so much like the 2° Celsius target for climate change