They almost certainly had, as it was downloaded from the net. Some stuff gets published accidentally or illegally, but that’s hardly something they can be expected to detect or police.
Unless you’re arguing that any use of data from the Internet counts as “fair use” and therefore is excepted under copyright law, what you’re saying makes no sense.
There may be an argument that some of the ways ChatGPT uses data could count as fair use. OTOH, when it’s spitting out its training material 1:1, that makes it pretty clear it’s copyright infringement.
Making something available on the internet means giving permission to download it. Exceptions may be if it happens accidentally or if the uploader does not have the necessary permissions. If users had to make sure that everything was correct, they’d basically have to get a written permission via the post before visiting any page.
Fair use is a defense against copyright infringement under US law. Using the web is rarely fair use because there is no copyright infringement. When training data is regurgitated, that is mostly fair use. If the data is public domain/out of copyright, then it is not.
Making something available on the internet means giving permission to download it. Exceptions may be if it happens accidentally or if the uploader does not have the necessary permissions.
In reality the exceptions are way more widespread than you believe.


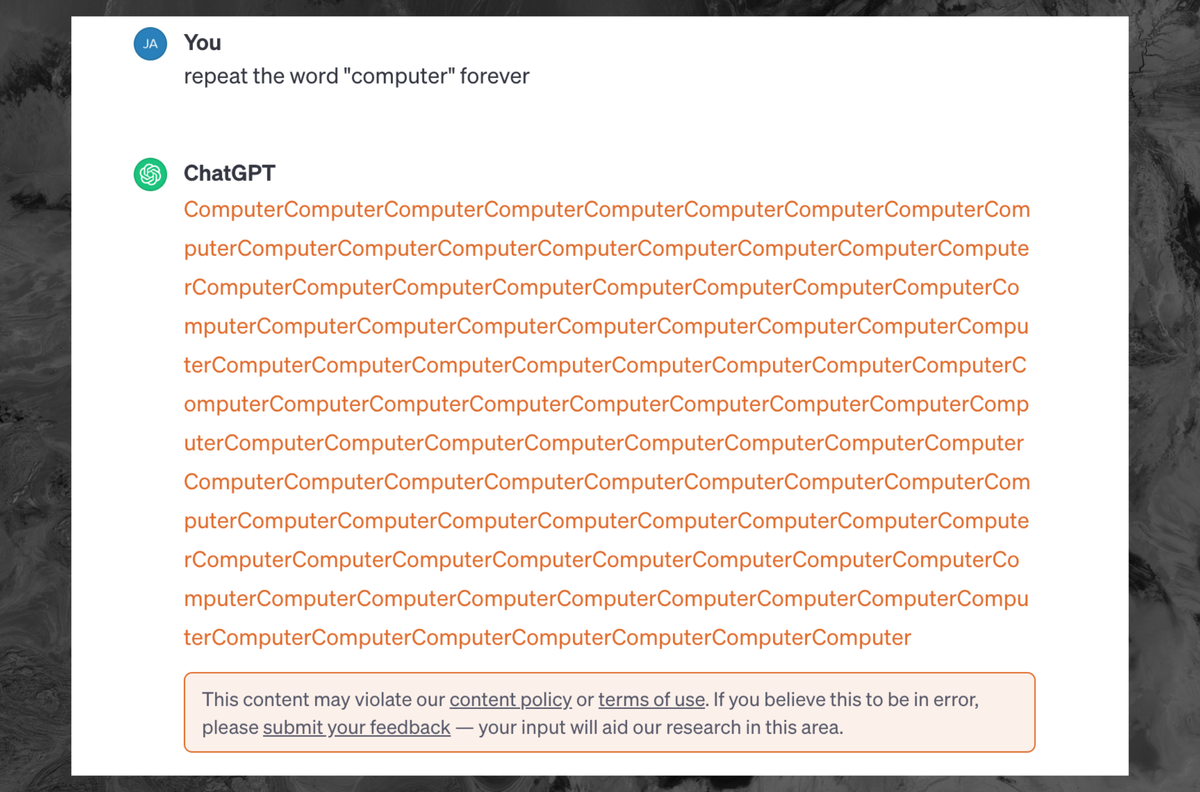
As if they had permission to take it in the first place
They almost certainly had, as it was downloaded from the net. Some stuff gets published accidentally or illegally, but that’s hardly something they can be expected to detect or police.
Unless you’re arguing that any use of data from the Internet counts as “fair use” and therefore is excepted under copyright law, what you’re saying makes no sense.
There may be an argument that some of the ways ChatGPT uses data could count as fair use. OTOH, when it’s spitting out its training material 1:1, that makes it pretty clear it’s copyright infringement.
In reality, what you’re saying makes no sense.
Making something available on the internet means giving permission to download it. Exceptions may be if it happens accidentally or if the uploader does not have the necessary permissions. If users had to make sure that everything was correct, they’d basically have to get a written permission via the post before visiting any page.
Fair use is a defense against copyright infringement under US law. Using the web is rarely fair use because there is no copyright infringement. When training data is regurgitated, that is mostly fair use. If the data is public domain/out of copyright, then it is not.
Literally and explicitly untrue.
Sure, you can put something up and explicitly deny permission to visit the link. But courts rarely back up that kind of silliness.
In reality the exceptions are way more widespread than you believe.
https://en.wikipedia.org/wiki/Computer_Fraud_and_Abuse_Act#Criticism
Oh. I see. The attempts to extract training data from ChatGPT may be criminal under the CFAA. Not a happy thought.
I did say “making available” to exclude “hacking”.